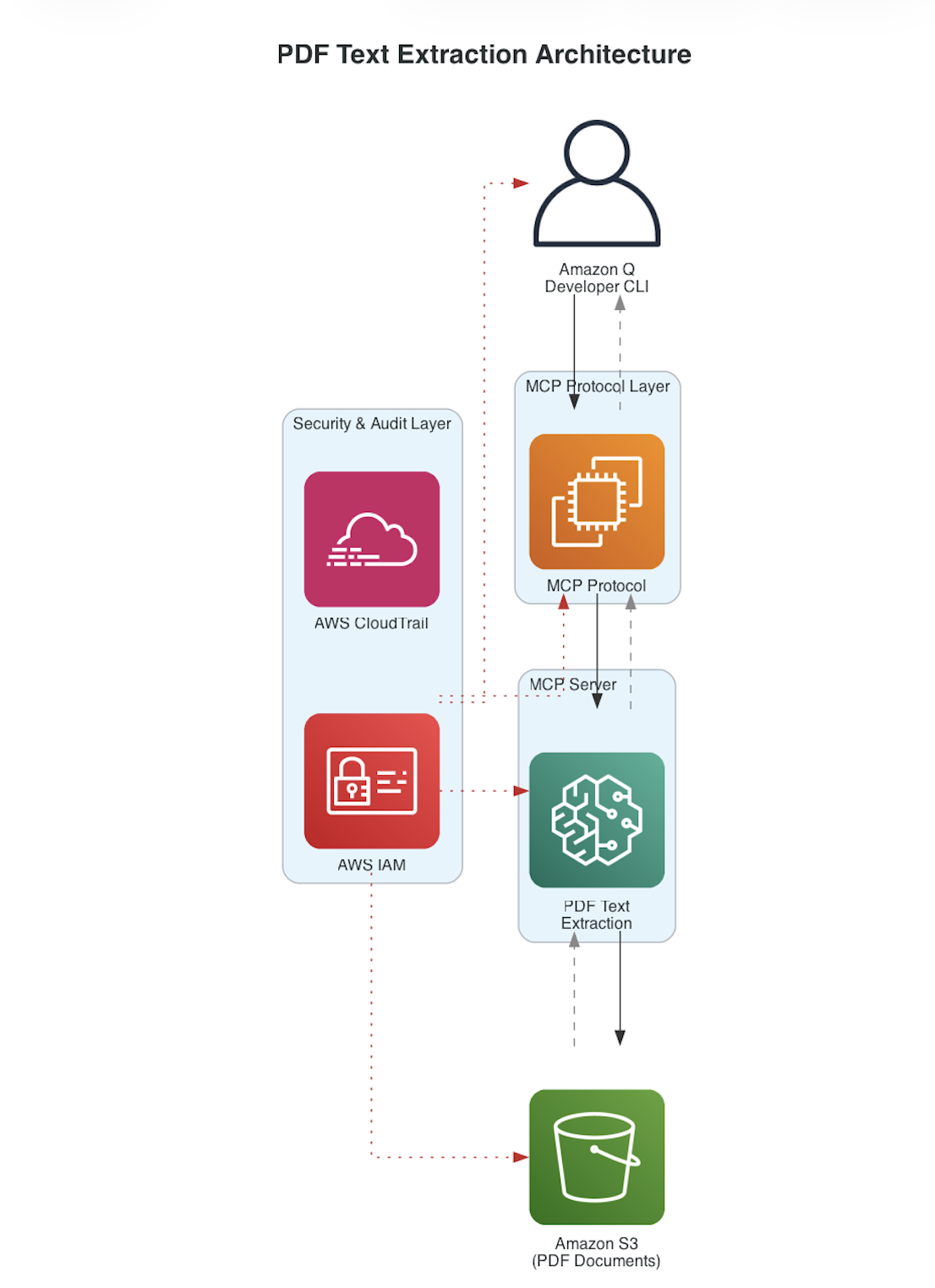
In this post, you’ll build a server that extracts text from PDF files in Amazon S3 in real time. This protocol-based approach provides programmatic document access. You’ll walk through the architecture, set up the server, and run interactive document queries. Along the way, you’ll compare this approach with Amazon Textract so you can decide which tool fits your workload.
Source: AWS Machine Learning Blog — read the full report at the original publisher.