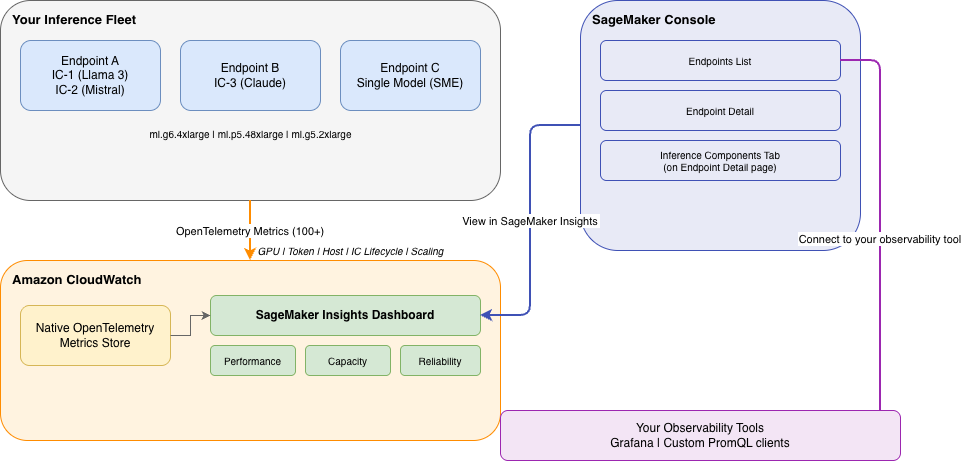
Amazon SageMaker AI provides fully managed real-time inference hosting for machine learning models. You deploy a model to a SageMaker endpoint backed by one or more compute instances, and SageMaker handles provisioning and scaling. SageMaker supports multiple endpoint architectures. This post focuses on the two most relevant to generative AI workloads with detailed observability: Single-model endpoints (SME) and Inference component (IC) endpoints.
Source: AWS Machine Learning Blog — read the full report at the original publisher.