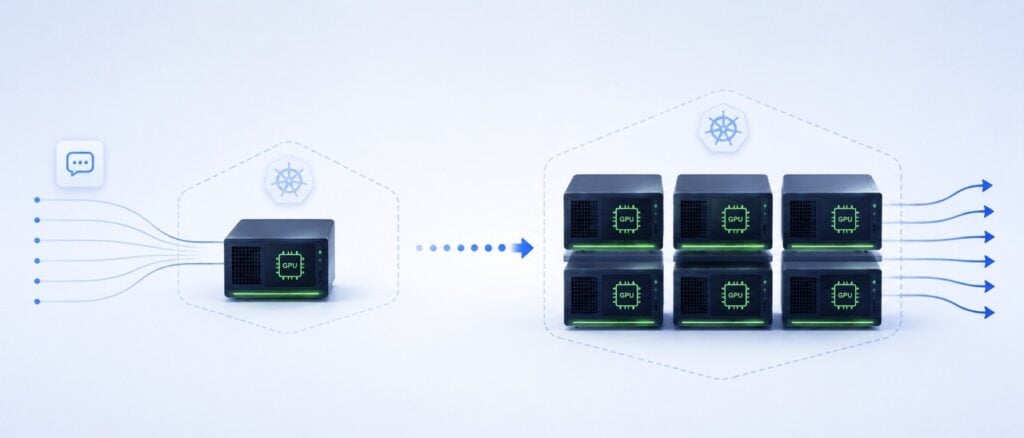
The rush to deploy Large Language Models (LLMs) and generative AI has created a massive infrastructure bottleneck. Platform engineering teams are spinning up expensive GPU node pools on Kubernetes, but they are quickly realizing a painful truth: standard Kubernetes scaling mechanisms were not built for AI. When an AI inference The post Stop Wasting GPU Budget: Autoscaling AI Inference on Kubernetes with KEDA appeared first on Cloud Native Now .
Source: Container Journal — read the full report at the original publisher.