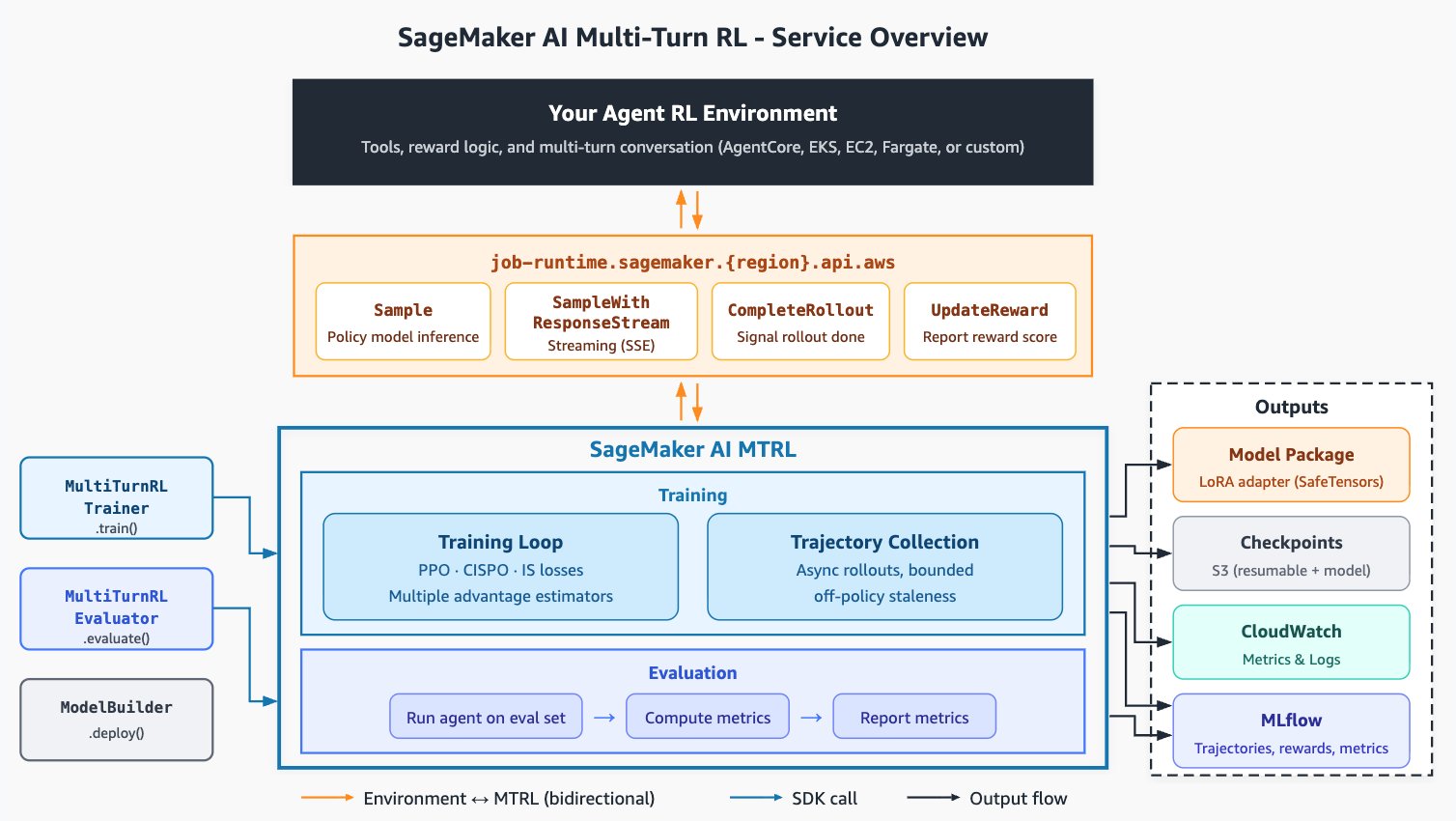
In this post, we share best practices for reliable multi-turn RL training. We cover how to build a training environment you can trust, set up an external evaluation, design a reward aligned with the end task, manage what changes once the agent runs for multiple turns, and monitor the metrics that tell you when to iterate.
The rapid advancement in AI, particularly within reinforcement learning, necessitates practical guidance for complex, multi-turn applications. Cloud providers are actively publishing best practices to accelerate adoption and demonstrate capabilities.
Reliable multi-turn reinforcement learning is crucial for developing sophisticated AI agents capable of sustained interaction and complex task execution, pushing the boundaries of AI automation. This directly influences the speed and efficacy of AI agent development and deployment.
The publication of these best practices makes it easier for developers to build robust multi-turn RL systems, potentially accelerating the development of more capable and trustworthy AI agents. This reduces friction in operationalizing advanced AI.
- · AI developers
- · Cloud AI platforms (e.g., AWS)
- · Industries adopting AI agents
- · Customers using AI-powered services
- · Companies unable to leverage advanced RL
- · Legacy automation providers
More sophisticated and reliable AI agents can be deployed across various sectors, automating complex, multi-step processes.
Increased adoption of AI agents could lead to significant productivity gains and disruption of traditional white-collar workflows.
The enhanced reliability of AI agents could accelerate trust and integration into critical infrastructure, potentially raising new ethical and regulatory challenges.
This signal links to a primary source. Continuum Brief monitors and indexes it as part of the live intelligence stream — we do not republish source content.
Read at AWS Machine Learning Blog