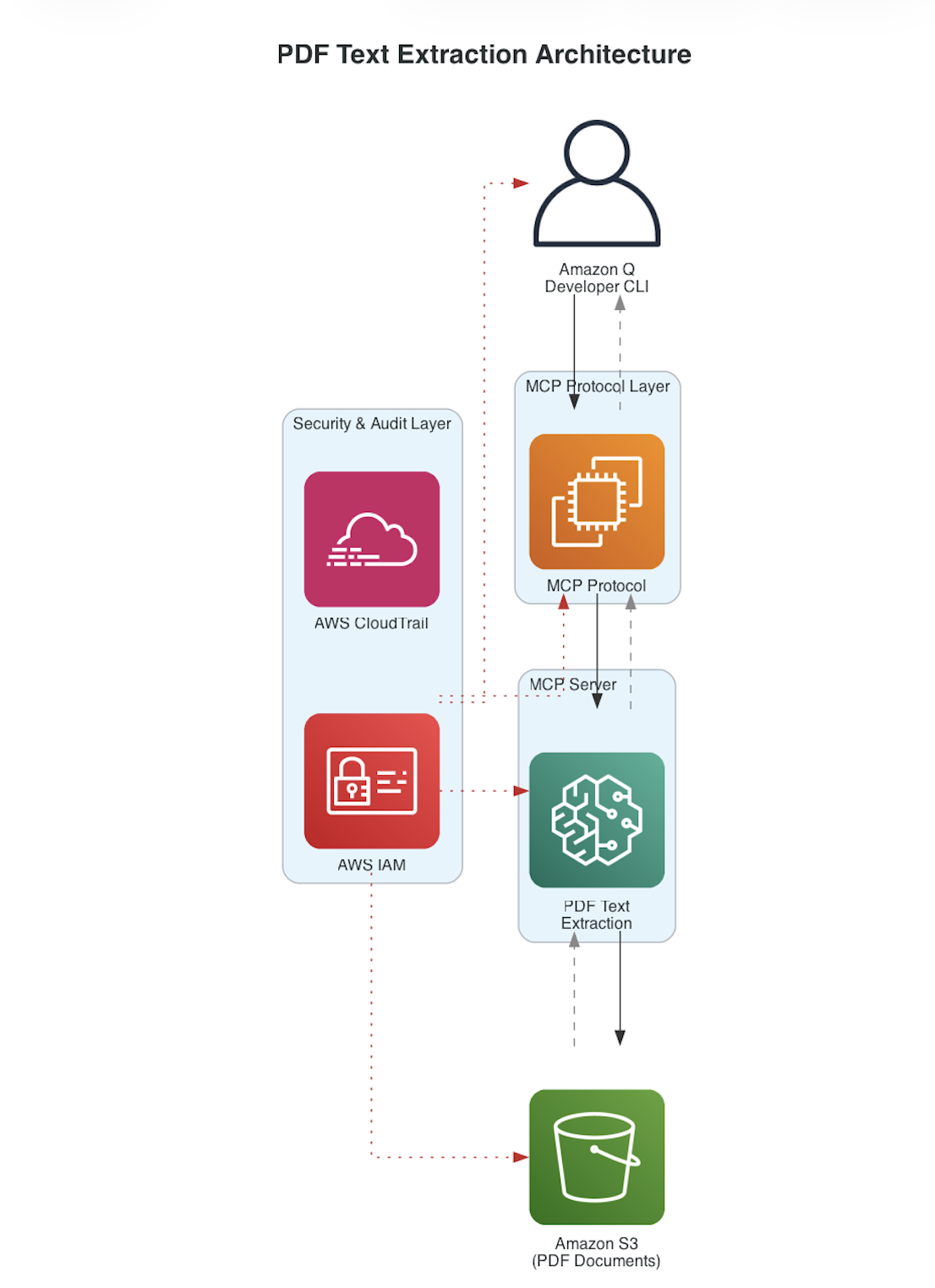
In this post, you’ll build a server that extracts text from PDF files in Amazon S3 in real time. This protocol-based approach provides programmatic document access. You’ll walk through the architecture, set up the server, and run interactive document queries. Along the way, you’ll compare this approach with Amazon Textract so you can decide which tool fits your workload.
This technical how-to is part of a continuous stream of content from cloud providers demonstrating feature utility. It aligns with the ongoing need for efficient data processing solutions.
While useful for developers, this specific post does not introduce novel capabilities or significant shifts in the AI or cloud computing landscape. It's an incremental update to existing functionality.
Developers gain a specific method for PDF text extraction from S3, potentially optimizing certain data workflows, but the broader technical or market structure remains unchanged.
- · AWS developers
- · Companies with PDF-heavy S3 archives
Increased efficiency for specific PDF processing tasks on AWS.
Slightly reduced friction for companies integrating PDF data into their AI/ML pipelines.
Minimal impact on the competitive landscape of cloud-based document processing services as this is a common offering.
This signal links to a primary source. Continuum Brief monitors and indexes it as part of the live intelligence stream — we do not republish source content.
Read at AWS Machine Learning Blog