Comprehensive observability for Amazon SageMaker AI LLM inference: From GPU utilization to LLM quality
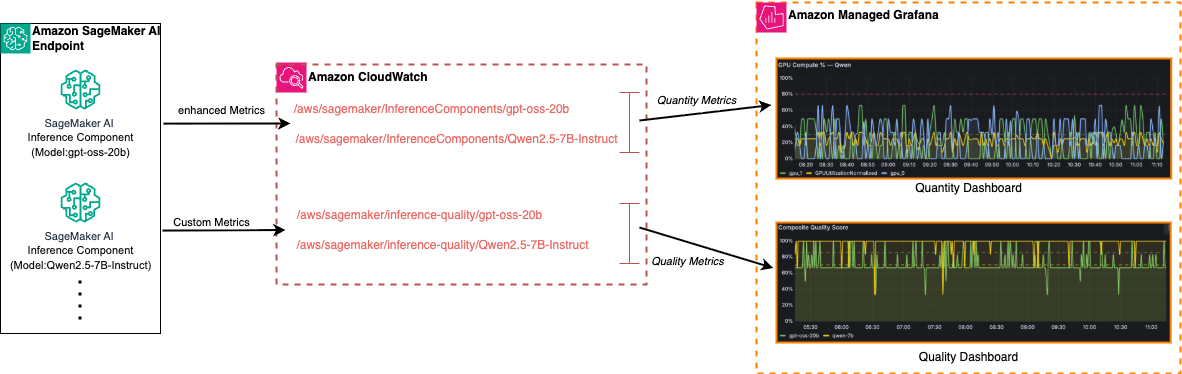
This post demonstrates a comprehensive observability solution using Amazon Managed Grafana dashboards that provides a holistic view of both quality and quantity for LLMs served on Amazon SageMaker AI endpoints with inference components.
The rapid deployment of LLMs in production necessitates robust tools for monitoring their performance and cost-efficiency, pushing cloud providers to offer comprehensive solutions.
This development indicates the increasing maturity of MLOps for large language models, allowing enterprises to manage, optimize, and justify the significant computational resources LLMs consume.
Enterprises can now more effectively monitor and debug LLM inference, leading to better model performance, reduced operational costs, and clearer ROI for AI investments.
- · AWS
- · Enterprises adopting LLMs
- · MLOps platforms
- · Data scientists & ML engineers
- · Companies lacking observability tools
- · Inefficient LLM deployments
Improved debugging and optimization of LLMs in production environments.
Accelerated enterprise adoption of LLMs as operational risks and costs become more manageable.
Enhanced competition among cloud providers to offer the most comprehensive and integrated MLOps and observability stacks for AI.
This signal links to a primary source. Continuum Brief monitors and indexes it as part of the live intelligence stream — we do not republish source content.
Read at AWS Machine Learning Blog