Debunking 8 data layout myths: why Liquid Clustering outperforms partitioning
IntroductionLaying out data is one of the oldest problems in computing. For over...
Data infrastructure continues to evolve rapidly, driven by the increasing scale and complexity of data, pushing for more efficient storage and retrieval solutions.
Efficient data layout directly impacts the performance and cost of large-scale data processing, which is critical for AI, analytics, and cloud computing.
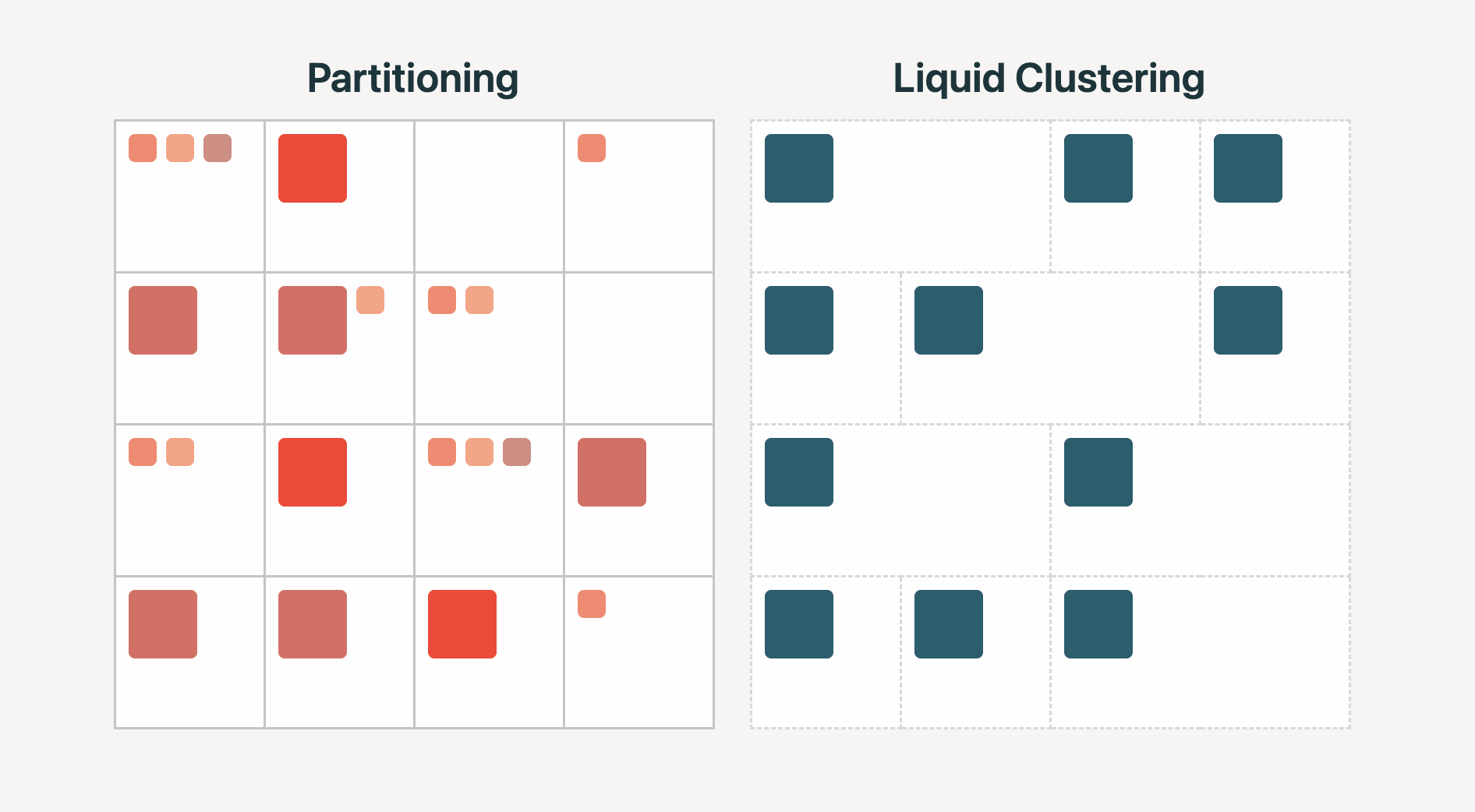
Databricks' Liquid Clustering offers an alternative to traditional data partitioning, potentially simplifying data management and improving query performance for large datasets.
- · Databricks (as a product-led outcome)
- · Enterprises with large data lakes
- · Data engineers and architects
- · Cloud data platform users
- · Legacy data warehousing solutions
- · Organizations slow to adopt new data lake architectures
Improved performance and reduced cost for data lakehouse architectures.
Increased adoption of Databricks' platform due to differentiated data management capabilities.
Further consolidation of the data management market around flexible, performance-optimized solutions.
This signal links to a primary source. Continuum Brief monitors and indexes it as part of the live intelligence stream — we do not republish source content.
Read at Databricks Blog