Monitor and debug generative AI inference with SageMaker detailed metrics and Insights dashboard on CloudWatch
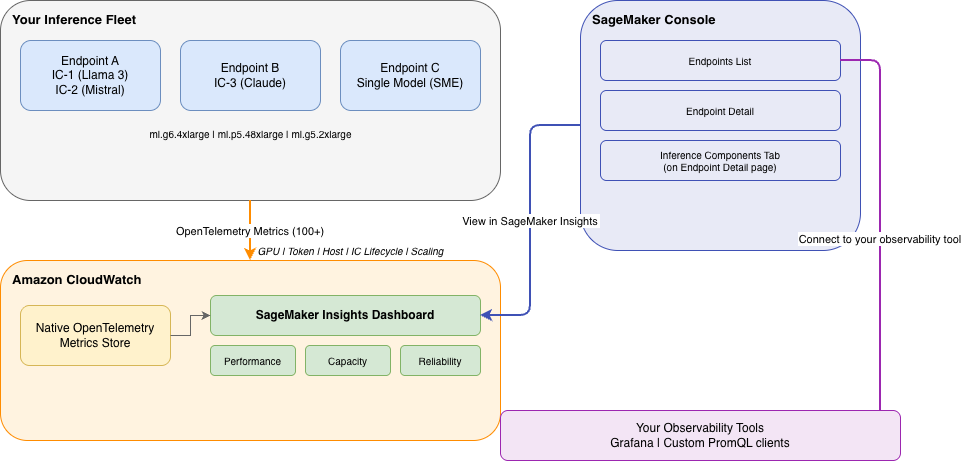
Amazon SageMaker AI provides fully managed real-time inference hosting for machine learning models. You deploy a model to a SageMaker endpoint backed by one or more compute instances, and SageMaker handles provisioning and scaling. SageMaker supports multiple endpoint architectures. This post focuses on the two most relevant to generative AI workloads with detailed observability: Single-model endpoints (SME) and Inference component (IC) endpoints.
As generative AI becomes more prevalent and critical for enterprises, the need for robust monitoring and debugging tools is increasing, prompting AWS to enhance its SageMaker offerings.
Improved observability in generative AI inference will lead to more reliable, performant, and cost-effective AI deployments, crucial for enterprise adoption and scaling.
Enterprises can now more effectively manage the operational aspects of their generative AI models on AWS, reducing deployment risks and accelerating development cycles.
- · AWS (Amazon Web Services)
- · Enterprises deploying Generative AI
- · MLOps Engineers
- · Data Scientists
- · Companies with less sophisticated monitoring solutions
Increased adoption and successful scaling of generative AI applications on AWS.
Heightened competition among cloud providers to offer superior MLOps tooling for advanced AI models.
Accelerated integration of generative AI into core business processes across various industries due to improved operational confidence.
This signal links to a primary source. Continuum Brief monitors and indexes it as part of the live intelligence stream — we do not republish source content.
Read at AWS Machine Learning Blog