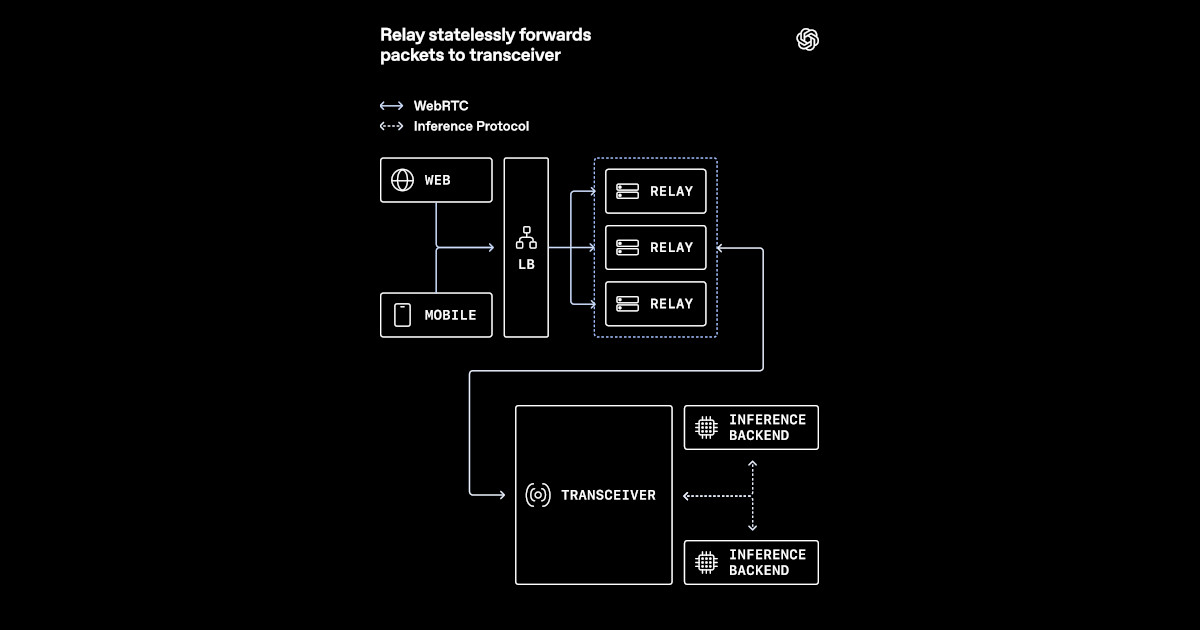
OpenAI recently outlined how it adapted WebRTC for low-latency voice AI at global scale. The new architecture replaced a conventional media termination model with a relay-transceiver design better suited to Kubernetes and cloud load balancers. It keeps WebRTC session state in a dedicated transceiver layer while using relays to reduce public UDP exposure and keep media routing close to users. By Eran Stiller
The rapid advancement and adoption of voice AI models necessitate robust, low-latency infrastructure to deliver real-time conversational experiences at global scale.
This development addresses a critical technical bottleneck for deploying advanced voice AI, enabling more natural and responsive human-computer interaction across various applications.
The architecture for large-scale, low-latency voice AI is evolving to better leverage cloud-native patterns, moving towards more efficient and scalable real-time communication infrastructure.
- · OpenAI
- · Cloud Providers
- · Developers of voice-enabled applications
- · Users of AI voice services
- · Legacy media termination architectures
- · Companies unable to scale real-time AI efficiently
Widespread deployment of highly responsive voice AI across customer service, personal assistants, and industrial applications becomes more feasible.
Increased user reliance on voice as a primary interface due to improved performance and reduced friction.
The development of new classes of applications and services that are only possible with ultra-low-latency, massively scalable voice AI.
This signal links to a primary source. Continuum Brief monitors and indexes it as part of the live intelligence stream — we do not republish source content.
Read at InfoQ