Stop Wasting GPU Budget: Autoscaling AI Inference on Kubernetes with KEDA
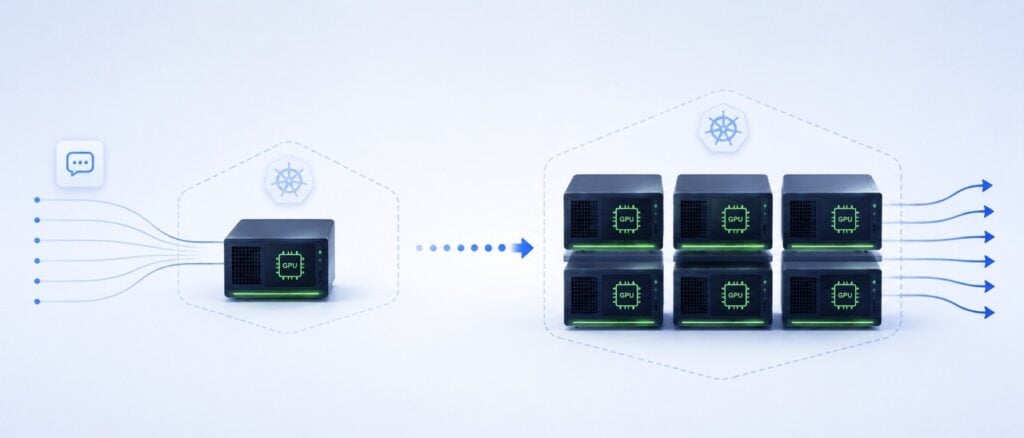
The rush to deploy Large Language Models (LLMs) and generative AI has created a massive infrastructure bottleneck. Platform engineering teams are spinning up expensive GPU node pools on Kubernetes, but they are quickly realizing a painful truth: standard Kubernetes scaling mechanisms were not built for AI. When an AI inference The post Stop Wasting GPU Budget: Autoscaling AI Inference on Kubernetes with KEDA appeared first on Cloud Native Now .
The rapid deployment of LLMs and generative AI has exposed the inefficiencies of traditional infrastructure scaling for GPU-intensive workloads, leading to urgent optimization needs.
This highlights a critical bottleneck in AI infrastructure, where inefficient resource allocation leads to significant financial waste and impedes further AI development and deployment at scale.
Platform engineering teams are now forced to adopt specialized autoscaling solutions like KEDA for AI inference, shifting away from generic Kubernetes scaling to more cost-effective and performance-optimized approaches.
- · AI software optimization companies
- · Cloud infrastructure providers (leveraging efficient resource use)
- · Organizations deploying AI inference at scale
- · Organizations with unoptimized AI infrastructure
- · Hardware vendors relying solely on raw GPU sales without considering efficiency
- · Standard Kubernetes scaling mechanisms for AI workloads
Reduced GPU expenditure for AI inference, making AI more accessible and cost-effective.
Accelerated development and deployment of complex AI models due to optimized infrastructure and lower operational costs.
Increased competition in AI model deployment as cost barriers are lowered, potentially leading to new business models and applications.
This signal links to a primary source. Continuum Brief monitors and indexes it as part of the live intelligence stream — we do not republish source content.
Read at Container Journal