When Your Cluster Won’t Sit Still: The Hidden Cost of Kubernetes Autonomy During Incidents
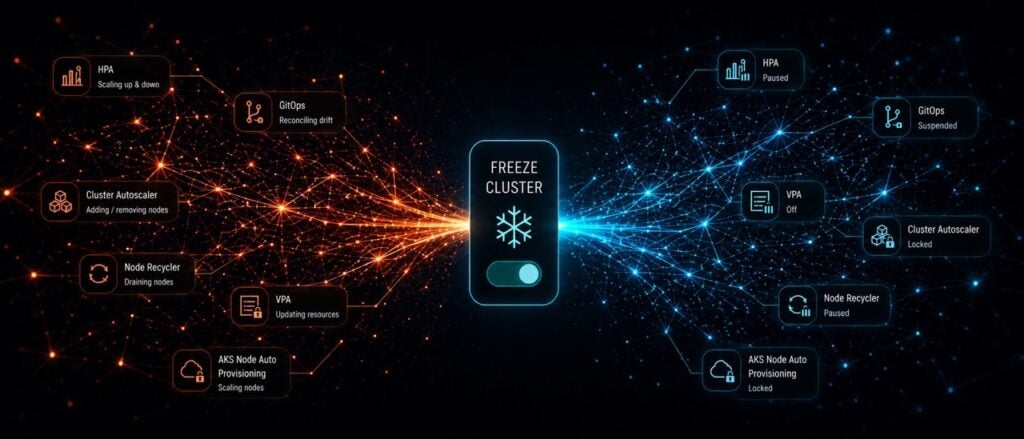
I’ve spent the better part of the last few years on the receiving end of Kubernetes pages, both as an operator and as someone building tooling for platform teams. The pattern I’ve seen, across very different organizations, is almost always the same: the hardest part of a Kubernetes incident isn’t The post When Your Cluster Won’t Sit Still: The Hidden Cost of Kubernetes Autonomy During Incidents appeared first on Cloud Native Now .
The increasing complexity and adoption of Kubernetes in critical systems are highlighting operational challenges, particularly in incident response, where autonomy can hinder rather than help.
Strategic readers should care as the hidden costs of Kubernetes autonomy during incidents point to a need for more robust, human-centric incident management tooling and strategies in complex infrastructure.
The focus is shifting from purely autonomous container orchestration to a more nuanced view that recognizes the need for granular control and human intervention in high-stress operational scenarios.
- · Incident response software providers
- · Platform engineering teams
- · DevOps tooling companies
- · Organizations with poorly defined incident response playbooks
- · Teams solely relying on autonomous systems
Increased investment in specialized incident management and observability tools for Kubernetes environments.
Development of industry best practices and standards for managing distributed system autonomy during critical events.
A potential re-evaluation of 'autonomy' as a design principle in complex infrastructure, favoring 'assisted autonomy' or 'human-in-the-loop' models.
This signal links to a primary source. Continuum Brief monitors and indexes it as part of the live intelligence stream — we do not republish source content.
Read at Container Journal